Validation · Proteomics
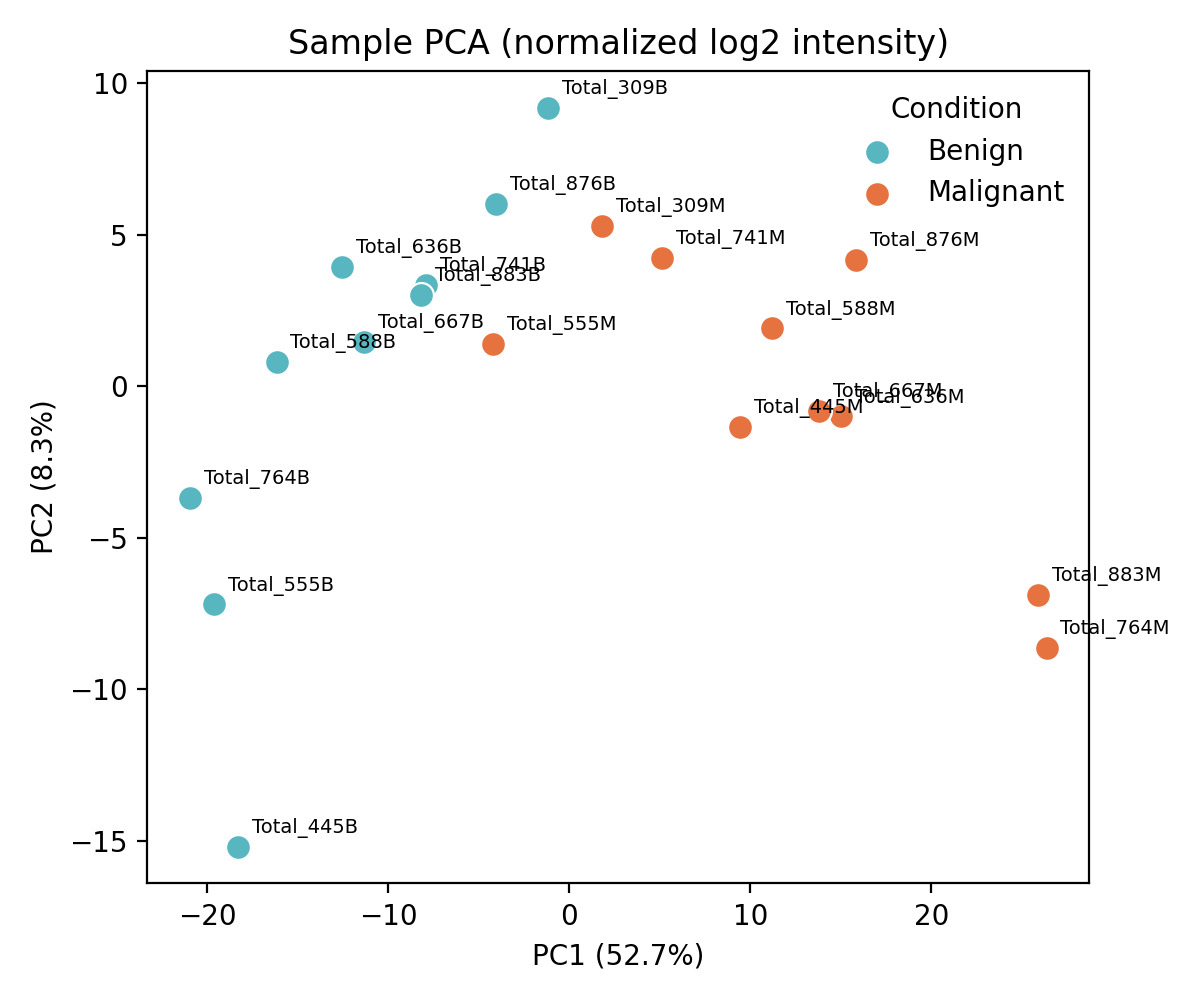
LFQ-Analyst tumour-vs-benign liver-tissue example, 10 patient-paired Benign/Malignant samples, LFQ-DDA MaxQuant
Tumour vs benign liver should recover complement / coagulation cascade enrichment (the most-replicated proteomic signal in HCC-like contexts), ECM organisation, and IGF/IGFBP signalling — i.e. textbook tumour-vs-adjacent biology.
4922 → 1708 tested proteins → 314 differentially abundant (FDR < 0.05, |log2FC| > 1) → 86 enriched pathway terms. Top hits: complement & coagulation cascades (KEGG, padj = 6×10⁻⁷), extracellular-matrix organisation (Reactome, padj = 2×10⁻⁶), IGF/IGFBP signalling.
LFQ proteomics pipeline benchmark on a canonical paired tumour-vs-adjacent-tissue dataset. The differential-abundance + pathway-enrichment layers correctly identify the dominant tumour-biology signals expected from a hepatic malignancy context.
Same pipeline, fixed-fee, 7–10 business days. Email with your omics type and sample count.