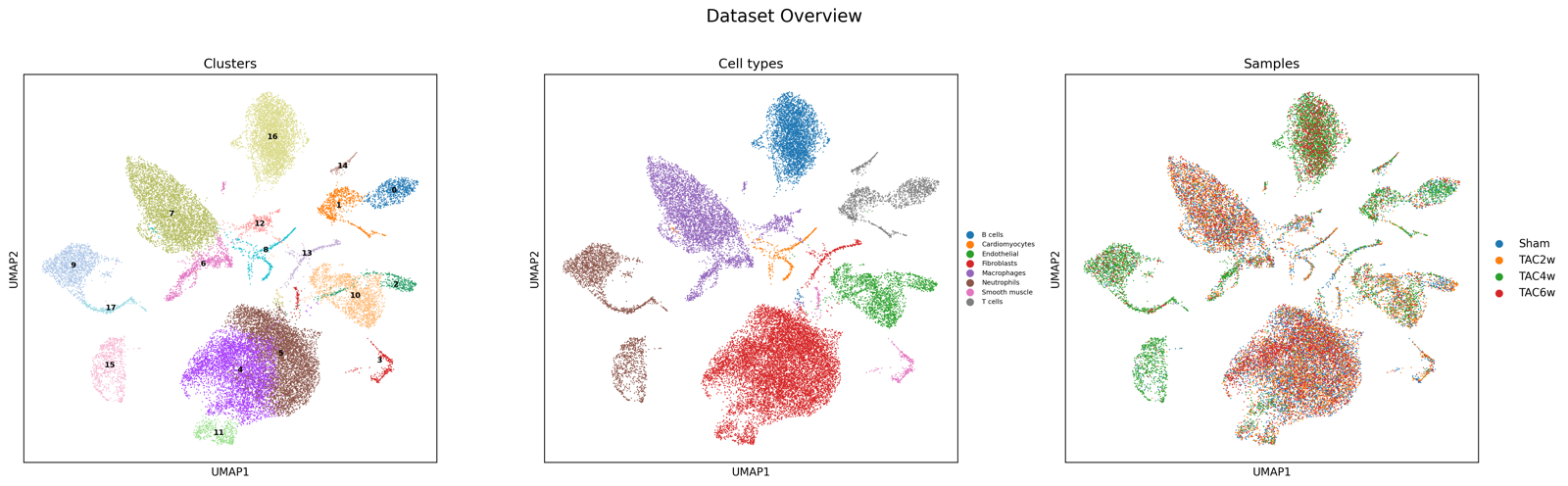
scRNA-seq
scRNA-seq pipeline — mouse heart TAC time course
GSE308859 — 4 timepoints (Sham, TAC 2w/4w/6w), ~27,200 cells, 10x Chromium
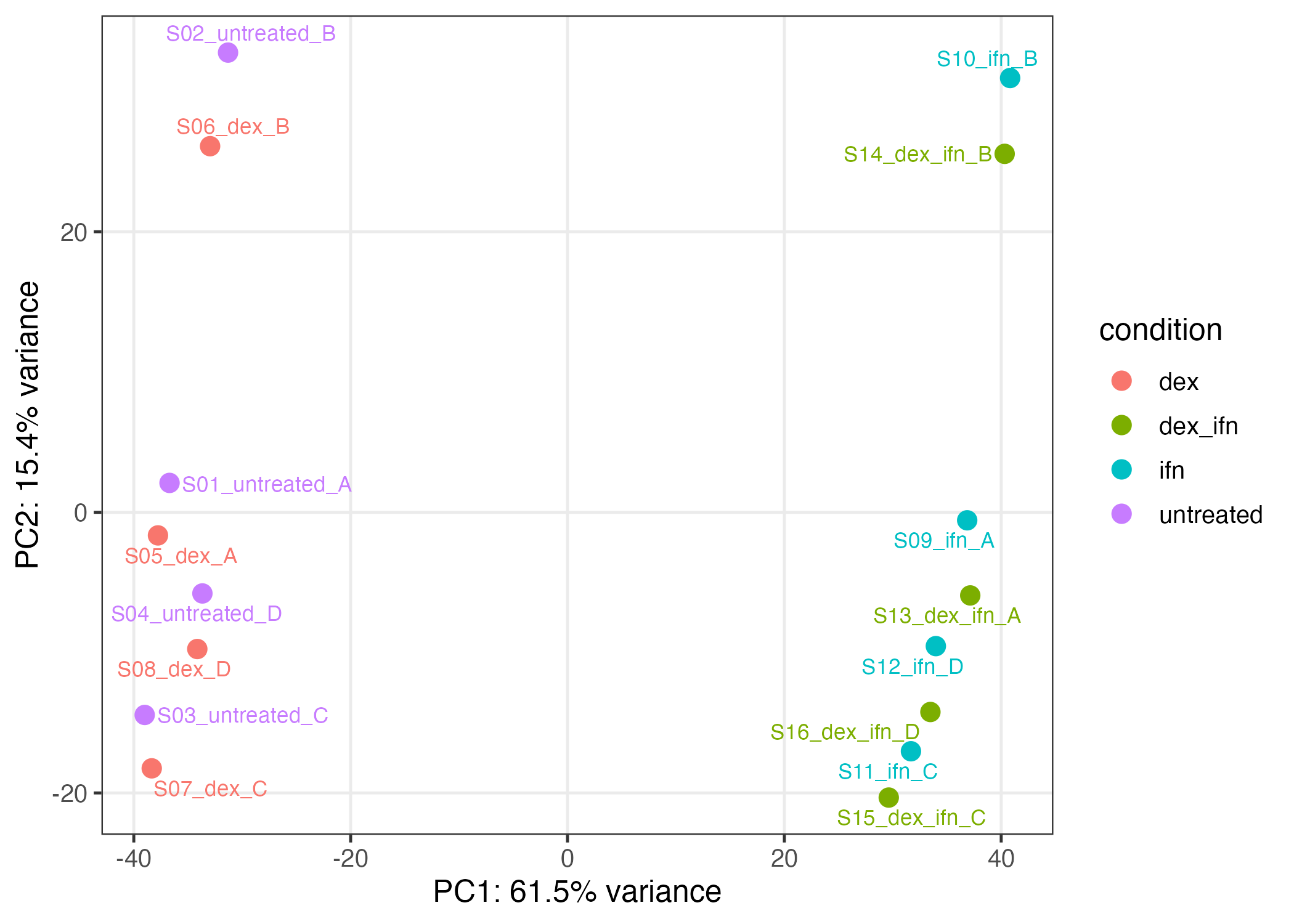
RNA-seq
Bulk RNA-seq pipeline — dexamethasone perturbation
Public RNA-seq dataset, dexamethasone vs DMSO in A549 cells (canonical glucocorticoid response benchmark)
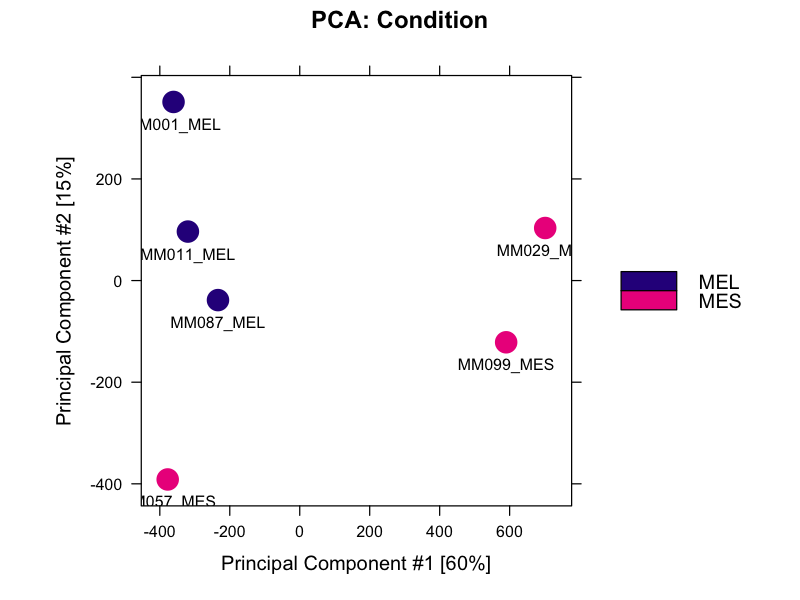
ATAC-seq
ATAC-seq pipeline — melanoma cell-line accessibility
ATAC-seq across melanoma cell lines, ~20 samples
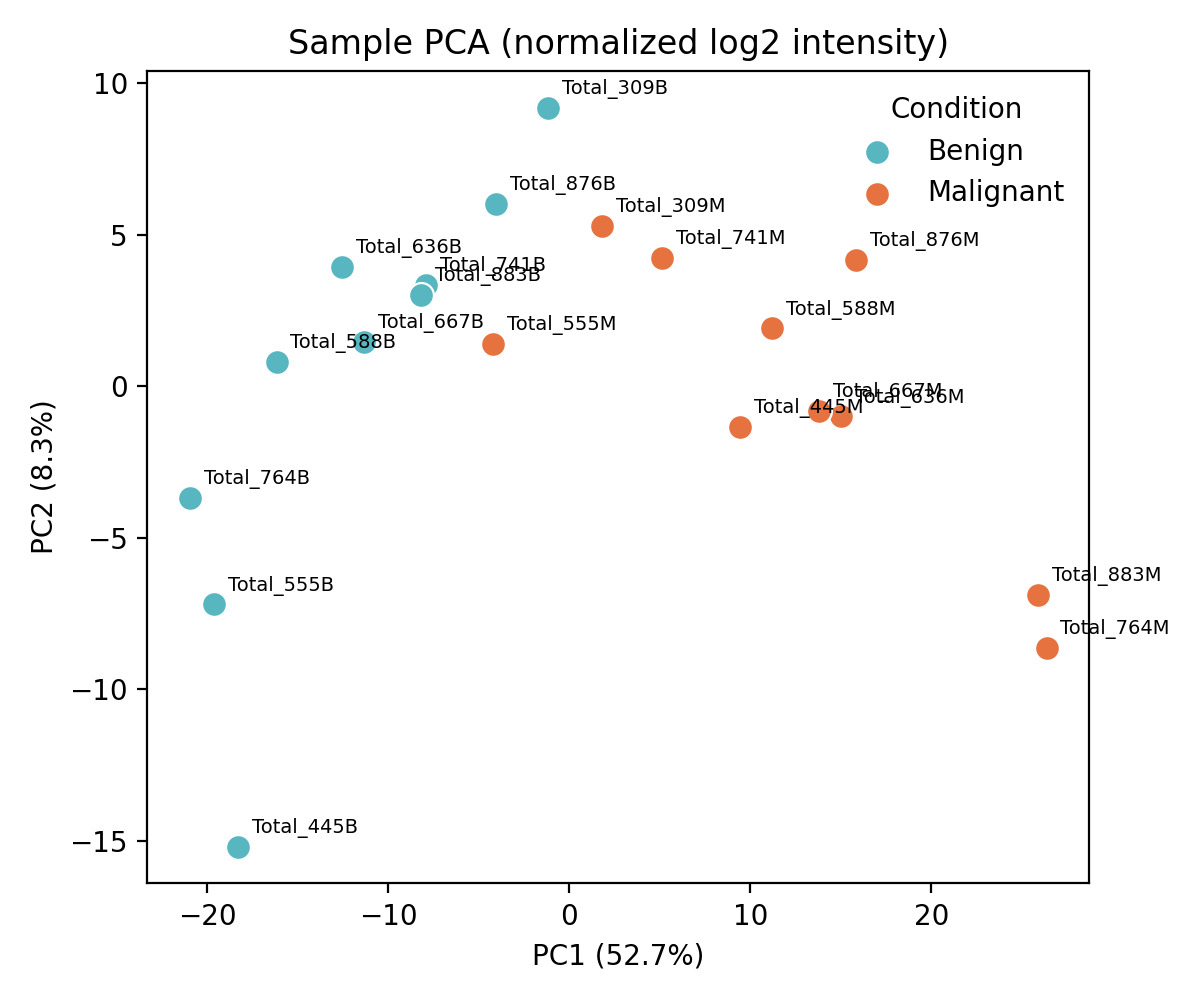
Proteomics
Proteomics pipeline — paired tumour vs benign tissue
LFQ-Analyst tumour-vs-benign liver-tissue example, 10 patient-paired Benign/Malignant samples, LFQ-DDA MaxQuant
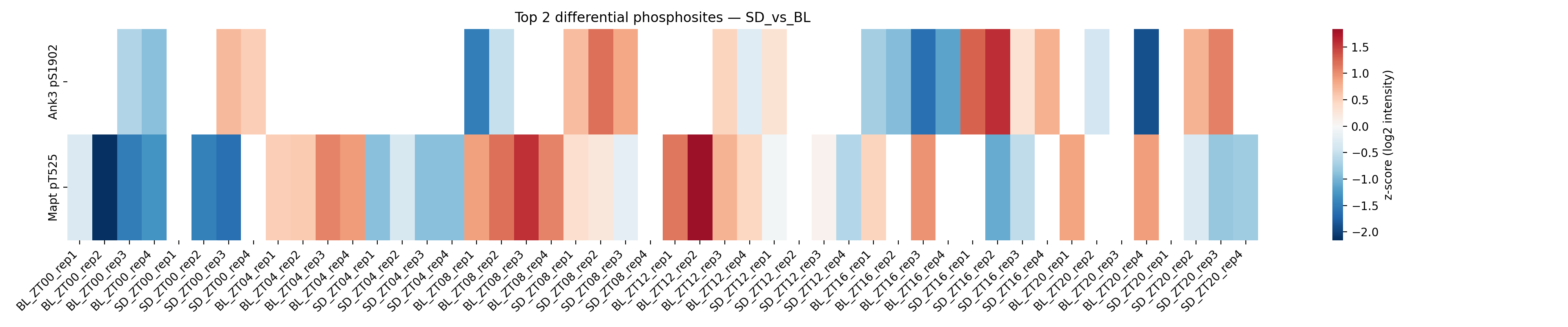
Phosphoproteomics
Phosphoproteomics pipeline — sleep-deprivation synaptosomes
PXD010697 — Brüning 2019, sleep-deprivation synaptosomes, 48 LFQ-DDA samples across 6 timepoints
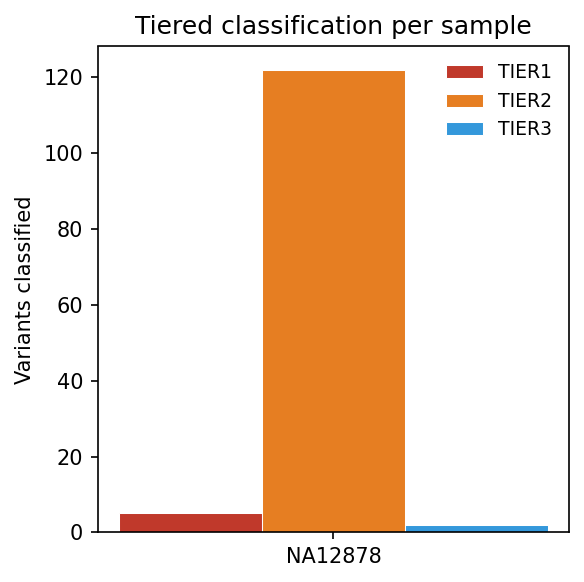
WGS
WGS interpretation pipeline — GIAB NA12878 chromosome 22
Genome-in-a-Bottle (GIAB) v4.2.1 NA12878 truth set, chromosome 22 (49,964 PASS variants)